{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/data/attach/topic/20251003/1759442554188_0.jpg', '推荐 cwshusheng 的文章《淘宝robots.txt限制搜索引擎抓取,背后原因你知道吗?》','https://tl.hwaiwenda.com/article-1500.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
你可有过这般好奇,于百度上搜索时分,为何搜不见淘宝商品了,探寻这背后的缘故呀,其实是商业博弈在流量聚焦层面予以控制呢,而其中发挥关键作用的工具就是那个称作robots.txt的文件 。
robots.txt 的作用机制
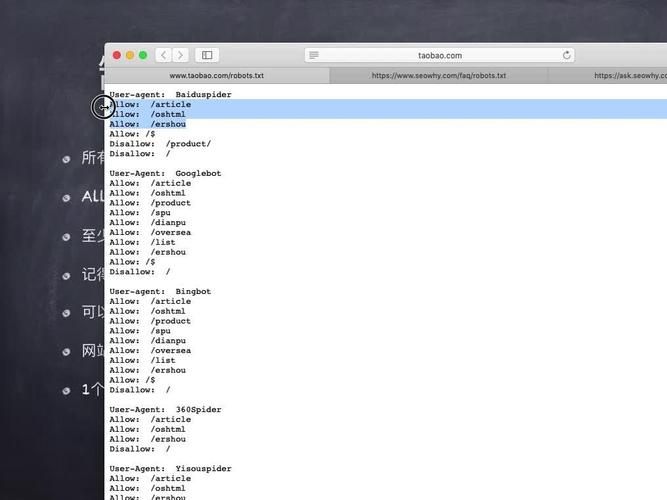
robots.txt属于文本文件类别,它所在的位置是网站根目录地方,这个文件的作用是向搜索引擎爬虫程序说明什么样的内容可以抓取,哪些是要避开的,举例情况如下,淘宝的robots.txt文件里对主流搜索引擎访问其商品页面有明确限定,也就是百度等搜索引擎在开展爬虫扫描时,会自动跳过淘宝所设置的禁止区域 。
这种机制不是仅仅淘宝自身所拥有,好多大型网站会运用它去保护特定内容或者页面,通过合理配置robots.txt,网站管理员能够有效地引导爬虫行为,还能确保重要数据不会被公开索引,并且降低服务器无关紧要的负载。对于普通用户来讲,这个过程一点感觉都没有,它只会对搜索引擎的数据收集环节产生影响。
淘宝的商业考量
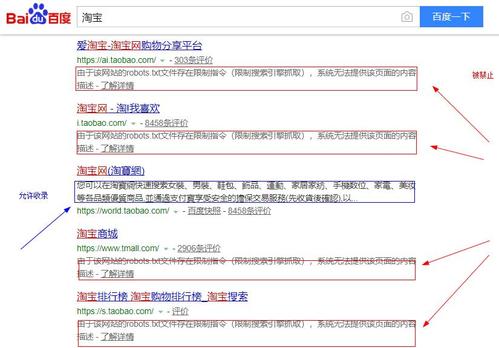
从商业运营角度出发,淘宝对搜索引擎抓取加以限制,其目的在于维持自身平台内部流量呈现闭合围绕的态势若准许百度搜索引擎直接索引全部商品许多用户或许会借助搜索入口径直走进商品页面进而凭借此种方式规避淘宝首页以及各类广告排位处这般便会导致淘宝内部流量分配机制无法有效发挥功用广告价值会大幅降低。
,这属于其作为电商平台的核心利益所在之处
搜索引擎的应对策略
淘宝进行了屏蔽行动,百度和其他搜索引擎实际处在被动情形下,遵守robots.txt协议是行业基本规范重点,采取强行抓取手段可能面临法律风险,可是完全搜不到淘宝平台相关内容,这般便会直接影响到用户通过搜索取得信息的体验,还有可能因搜不到想要找寻的内容而选用别的搜索引擎。
由此,百度采取了折中的方案!该方案为淘宝开设一个专门的入口通道,在搜索结果里引导用户前往淘宝主站进行搜索。既要尊重淘宝屏蔽指令,又要在一定程度上满足用户搜索需求,属于规则限制状况下的灵活变通。这么做目的在于减少用户流失数量,以维持自身在市场当中的价值。
行业规则与违规案例
在各式各样的行业协议当中,存在着一个为行业内宽泛而普遍认同的机器人排除标准协议就是robots.txt ,其具备的对所约束各对象的强制力和约束性,高度主要是架构搭建于行业往来各方自觉自愿去遵循依照的基础之上 ,在过往漫长的发展历史进程里,曾经出现过对协议约定内容进行违背反抗的事例情况 ,举例来说有着像360搜索进行的抓取百度知道、百度用户交流互动平台百度贴吧等被禁止不准去获取触碰的内容信息行为 ,最终因为这种违规行为而被百度方面告到关乎法律的层面上 。
最终,360被认定存在违规的行为举动,并且需要作出相应损失的赔偿,这样的一个案例,使得robots.txt在实际运用当中的法律效力得到了强化,它同时也提醒了其他的从业者,就算在技术的层面上有着突破相应限制的能力,也不可以随随便便地去违背已经确定好的爬虫协议,不然的话,就有可能引发不必要的法律方面的纠葛,以及声誉层面的损害。
对普通用户的实际影响
那对于日常使用的人来讲,淘宝将搜索引擎抓取予以屏蔽,几乎不会给他们带去任何不便,绝大多数的用户已然养成直接打开淘宝 APP 亦或是网站去搜寻的习惯号外资源网,甚至对 robots.txt 的存在都并不清楚,平台自身所拥有的搜索功能完全能够满足购物需求。
真正受到影响的,是搜索引擎索引范围,是结果呈现,你在百度搜不到淘宝内具体商品,不是因为淘宝网站无法访问,而是因为百度没抓取到那些页面数据,如此的设置使得用户行为数据更集中于淘宝自身,这对它优化推荐算法是有利的。
互联网生态的平衡之道
于本真意义来讲,robots.txt协议旨在网站方与搜索引擎间构建一种平衡机制,此机制助力保护敏感信息,能有效控制流量来源,可规范抓取行为,还能避免过度收集,对维持互联网各方面利益的相对稳定有一定作用 。
平台经济模式持续不断发展,类似淘宝那样采用封闭型生态的做法会越来越多,它们凭借对外部抓取加以限制来巩固自身流量池,这种情况虽然短期内可能对信息开放性产生影响,但是从商业竞争的角度来讲,也能够把它视作平台维护自身核心价值的一种合理手段 。
读完以上已完成的相关分析后请问,你是否觉得大型平台针对屏蔽搜索引擎抓取所采用的这般做法,最终对普通消费者来说是有利的。热忱欢迎去评论区分享自身看法,若你觉得本文能有帮助作用,也请点赞给予支持!